Back in the mid-2000s I worked on a scaled system that used memcache, and developers fell victim to all the exact same problems that are cited with Redis in the article.
- Developers attempting to endrun every one of the laws of distributed systems by using memcache.
- We had cache addiction, so the fleets got sized on the assumption that memcache was up, and then memecache had a problem, and suddenly we were DDOSed.
- write amplification, where one host would nuke a high-TPS key and every other host would DDOS a dependency to repopulate the key.
- hot keys which led to hot hosts and because we cohosted memcached with the service daemons, it meant mystery CPU spikes.
- stickiness from stale DNS entries causing memcache calls to blackhole.
Every single one was avoidable by using memcache in a better way, but the temptation to abuse it was too strong.
Personally I'd use memcached or some equivalent for strictly cacheing, and then bring on Redis with persistence if you need its data structures for e.g scoreboards.
At $WORK we never imported either, our cache layer for slow operations keeps its data in both the filesystem and a db table (used as a k/v store). The database helps coordinate thundering herd problems - this operation is being calculated by another thread, so just wait for it. Reads from the same server just hit the filesystem, and reads from another server hit the db once and then keep it in the filesystem. We could change the fs layer to memcached but so far it's working great.
Redis was definitely more featureful, and antirez is both an engaging character and admirably humble, so I can see why redis overtook it in popularity - but, for me, memcached has always been the pinnacle of "choose boring technology".
As a platform engineer, I'm happy to support either - but when developers start using some of the more advanced redis features (persistence, replication, clustering), I try to make sure that they've fully understood the downsides of that decision.
This so much. (Ab)Using a db table as a k/v store + the FS can do so much before even considering paying the price of setting up a dedicated caching store. I’ve fought countless foes in the engineering world when proposing solutions like yours just because (incompetent) people feel like caching should live in its dedicated store.
* Outages where Valkey had no memory policy, ate all the memory, and then caused write errors to its append-only file. Bonus points for another one where the disk itself was full, and AOF writes failed.
* 500s where Redis was fully expected to be live, running, and populated with data for every user, and no fallback to a slower path.
* Creative uses of sorted sets and other data structures which depended on the sets never being evicted.
Despite the observations from the field, I think it's still hard to recommend memcache ahead of Redis. It can be difficult to architect an app to have a memcache-friendly cache layout.
I'd almost guarantee a large enough team using memcache will find a way to need Redis. And then we're maintaining 2 cache technologies.
Honestly designing your app to have a "memcache-friedly cache layout" is the same thing as designing it to have a redis-friendly cache layout. The pattern for this kind of application cache is identical: "get, and if not there, calculate and set".
var value = cache.lookup<T>(
keyname,
() => db.query<T>(...),
TimeSpan.FromMinutes(5) // or CacheOptions
);
More features mean more users. Some stick to the old stuff, some embrace the new, and eventually certain values become the de facto default, not really optional anymore.
Take Redis. Turn off AOF and it works as a volatile in memory cache. But most of us don't even think about it that way. So there is this argument that fewer features and simpler is better.(Memcached is such an example in this context) The so called 'straitjacket' approach. That makes total sense for big teams. But on the other hand, open source projects need regular updates to keep getting funding or contributions, so there is a built in tension.
And sometimes that leads to specialized forks or spin offs that excel in one niche area. My personal take? There is no right answer. It all depends on the context. Communication itself isn't free, after all
Off topic, but that's my problem with microservices, devs seem to be totally unaware of this.
I think that’s because people replaced Memcached with Redis, and expect the same from it.
I used it with Ruby on Rails for many years. It sped up pages, and just worked.
The downside (and upside for speed) is (and always was) that cache was saved in memory not disk. This meant hosting would be expensive if you have a large scale site with a wide amount of data to cache.
Solid cache has been a savior for those cases for me. We have over 100gb of cache for a project I'm working on, and it's stored in postgres on disk, with fast lookups with an index and expirations that happen automatically in Rails to delete those rows.
If I had a smaller cache need and was already using Redis, I'd probably just use that. But if speed was the number 1 factor, and I'd try benchmarking Memcached vs Redis.
Perhaps that's because I'm not giving admin access to random people who think that Redis is a persistent storage, but honestly it's one of those technologies I'd describe as absolutely rock solid and well designed. The API is dead basic and every time I need to do something slightly weird, there's a sensible and well thought out way to achieve it.
It's not bad enough where I had to pull it from the old project that used it, but going forward the new ones used a vibecoded queueing system that was genuinely more reliable than Celery but consumed a lot of memory (RSS inflation). Have then shifted to rq and at least for now it seems to "just work". You're better off doing anything custom/complex (like dependencies, or progress updates across multiple tasks) directly yourself in Redis anyway; since half the time Celery's less-well-trodden inbuilt features don't work the way they should anyway.
How did you find your expectations and celery's actual semantics to be different? I'm trying to document well and it seems like I might have some implicit assumptions that I could make explicit, but I don't know what they are since they're already in my head and matching celery it seems.
If you answered no to each question, just `import Queue from queue`.
Things like provisioning, deploying, and eventually destroying cloud instances (VMs) on-demand when a user buys a specific service.
> Do you need to be able to recover from a reboot or crash with your queues intact?
Yes, I expect the queue to be durable.
> Is it a distributed system as opposed to a single machine?
Currently, everything runs on a single machine. But I expect it will eventually have to be split up. Although I do not expect it to be massively distributed or very complex.
> Do you have complex multi-step workflows?
Depends on what you mean by complex but Multi-step, yes.
In my world cache systems like memcached and redis are just that, a cache to put and get from. Possibly use some invalidation system like tagging.
What can you do with a cache system that is 'wierd'? What are people doing with caches other than just caching data?
Genuinely interested.
- Rate limits for API endpoints via the leaky bucket algorithm
- Feature flags and stats tracking
- Websocket pub/sub
- Background job queue
In general, lots of things that need to survive deploys (so they can't be in-memory in the app) and/or they need to be coordinated across multiple horizontally scaled servers and/or things that prefer to be in a data structure which is slightly awkward to stick in a database table.
At some point someone decided to gzip all writes into memcached, and our site looked really fun for a while.
That requires some weirdness
So does that mean you are tracking how many times data is being entered into redis, and rejecting it if the entry rate is too high?
Why would you not track this before, at the point of calculating the data to enter into redis, rather than querying redis to see how much data is entered in a given timeframe?
Again, genuinely curious as to the reason for architectural decisions.
This is fairly easy to do if your apps runs on a single server, but many companies run multiple servers and load balance requests among them. Those servers need some sort of coordination mechanism to keep track of the rate limits and their current state. Redis has dedicated instructions these days to do this, and in the old days there were plethora of libraries that use embedded Lua scripts to do the same thing.
I don't exactly remember how i implemented it, but it basically did a single call to redis to count the request for the IP and check the limits.
Another usecase where the more advanced data types & operations of redis are usefull, is for job queues, since you can atomically move a job from the 'queue' to the 'processing' list, thus preventing loosing jobs if the processor crashes after pulling it orso. But we do run all those on persisted redis stores, for safety :)
And if i would do it all again, i'd probably just use postgres for anything i want to keep when things crash. Redis just kinda lives between a 'real' database and a pure volatile kv-cache
The comparison is especially weird as memcached is also not persistent.
Ultimately though, regardless of whether you’re experience is true for the wider industry or not, if you’re letting a junior dev who refuses to read product documentation the responsibility of architecting production systems, then your problem isn’t Redis.
Also, because it's so easy to setup, most DevOps/SREs/Ops just chuck into production without reading about which flags to set because we are not informed it's a requirement until 11th hour.
Maybe the client libraries can help by returning nulls 10% of time, in dev mode?
That said, it's interesting when you learn in practice that sometimes an N+1 problem is actually faster as N+1 than trying to query across separate DBMS systems.
This is specially visible in SQLite workflows.
The roundtrip for querying a local SQLite file is so fast that it's passable to execute N SELECTS inside a loop instead of a single SELECT with a JOIN, for example.
at notion we use redis for a lot of things, but actual caching we leave to memcached
Just trying to get a sense of where people draw the line.
The most common first thing to cache is getting the current user, because this ends up being a very hot path for most stateless systems. Because you need to get the current user for almost every request, it's quite easy for getting the current user to be 50% of database load: first you get the user, then you do the thing. tada, user lookup is now half your app by volume
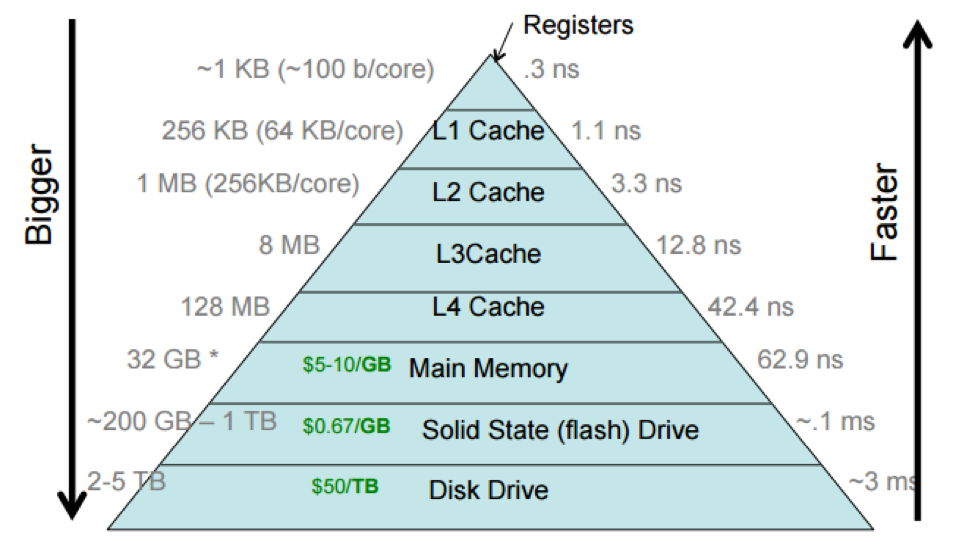
Look at this image: https://cs61.seas.harvard.edu/site/img/storage-hierarchy.png
At scale, the timing and order of magnitude increases in latency can add up. Caching the most requested data the higher you go can keep up performance (at added cost). On a busy website, that could be things like session tokens or other data that is part of every request. On a landing page, it could be images or other static data (I mean, you'd use a CDN for this, but you get the idea). Database calls can be expensive (computationally and IO wise), so if you can recalculate and cache certain operations, you can keep up.
Also, do you really need memcached/redis? If you have session affinity, you can also have nodes each keep their own caches in memory, with the caveat that if there's a failover, you'll have to re-fetch the data. Redis/memcached would be more of a shared cache, for things that you may not want to interrupt the user if they hit a different front-end endpoint.
It also doesn't have to be a cache. We've used redis for distributed task coordination as a shared state with the caveat that if something happened to redis, we'd just restart the task.
TL;DR If you need a SHARED cache when the performance of your app slows down enough that the cost of caching makes up for it.
One big tip I should recommend is to increase the default memory size limit to something more realistic for modern hardware (and arguably this should just be increased on the upstream's side as well, instead of making everyone reconfigure shitty defaults). It's very easy to exceed the memcached default key value, since it's just 1mb; the maximum size of memcached as a whole is 64mb, which is similarly very low. Outside of that, it works very well and the lack of persistence is great at making it not do things it's not supposed to do (which is a big problem with Redis' feature creep, the projects mainpage promoting AI drivel alone should point towards that.)
1) Wrap your client library so that it's impossible to store anything without an expiry date. You don't want 6-months-old data suddenly coming up in your app!
2) Either turn off persistence, or use a separate database for the cache. In other words, don't mix volatile data with stuff you actually care about.
3) Set up a reasonable maxmemory value with an appropriate maxmemory-policy, so that Redis doesn't eat up all your RAM.
4) Resist the urge to use complex data structures. If you try to update a single field on an expired hash, you will end up with an incomplete object.
If you don't want all that hassle, then yes, Memcached probably works better out of the box.
No need for this client-side complexity, as you should be using `allkeys-lru`. FWIW, should likely be doing this anyway, as (generally speaking) all data stored in Redis is usually regarded as volatile because of what Redis actually is.
If you know this already, then you didn't need to read OP or any of this thread. :)
The problem is that Redis tries very hard to position itself as a persistent data store, with defaults that lean toward persistence (no default eviction policy). Beginners need to fight these defaults every step of the way if all they want is a cache.
What are you talking about? On their website, the top 3 use cases (under the Platform menu) are: caching, streaming, and session management. Literally all of these three are volatile.
Never felt the need to go back to memcached except when a legacy dependency needed it.
What do you think of the argument made in the article?
Clustering redis is not that hard even if you do it manually and I have only had to do it once.
I never use redis persistence and have a max size set with LRU or whatever the application requires.
With memcached I remember having to mess around the LD_LIBRARY path to link whatever python module I was using at the time
Mature ops would be tracking cache hit ratios right?
It sounds like memcached would be really good in a use case where you really just need an optional stateless pure cache with absolutely zero rope to hang yourself on. A use case where "cache hit ratio" is the goal, not "fiddly in-memory data store".
Yeah I thought so too. Google "memcache slab starvation" if you want the long story
Sure, and sentry integrates well with redis in python which is what I use primarily with redis.
I don't think memcached is bad, I just think its old and industry has moved to redis because it offers more while covering the previous use case.
Calling redis fiddly is a mischaracterization. For many use cases I have not had to think more than 30s to setup redis.
(also when I say redis I mean Valkey at this point, even if they are starting to diverge)
Does your argument assume you already have a database, so you might as well use it for your cache mechanism?
APCu count=1000 min=0.000290 avg=0.000318 p50=0.000320 p95=0.000331 max=0.000992 ms
Memcached count=1000 min=0.032422 avg=0.039714 p50=0.037211 p95=0.053261 max=0.091343 ms
MariaDB count=1000 min=0.015680 avg=0.019541 p50=0.018485 p95=0.023855 max=0.103867 ms
Now then do a traceroute. Even to my router it costs 0.547 ms but that's only 1 direction. And a cloud space is hosting many servers, many routers, many switches, with lots of moving pieces so you're realistically adding 1.1 ms per subnet hop and in pretty much every data center that's probably 3-5 hops inside the LAN.
The real question, which few ever ask, is whether your app actually needs more than one server. Servers are so insanely large (up to like 400 Cores) and powerful now that you can get meaningful scale on a single box.
If you can colocate the app and cache (and maybe also the db) on the same server, you can get many orders of magnitude better performance, regardless of which cache it is. Redis, memcached etc all can do 100k or more gets per second (dragonflydb etc claim 10x that due to multithreading).
Hell, with RAM being so expensive now and NVME so fast, sqlite is a VERY attractive option for cache. Plenty written about projects adopting it. Rails in particular is a champion of it.
> Dealing with memcached downtime is incredibly easy, because client libraries generally ignore connection exceptions. For instance, a simple get will just return the default value (or none) if the server is down.
This is a terrible idea in the context of things that might use Redis. If you use Redis with some kind of complex state (say, a document if you're working on a Notion clone, for instance), wtf even is a "default value"? In fact, I actually also want to know when the thing is down.
> Clustering memcached is wonderful, because memcached actually has no clustering built-in.
Yeah bro, this is yet another one of the reasons people use Redis: it handles consensus and clustering for you. What even is this article? It's a master class in straw-manning architectural decisions: most people use hammers as hammers, but screwdrivers make great hammers too, especially if you also need to screw stuff in! I mean.. technically true?
Considering how complex and error prone this is, I don’t want it in my stack.
Have you ever used Redis before? I've literally never had to manage clustering or had any issues with it, and I've been using Redis for like 15 years (including for games where state had to live in multiple regions and could change on a 30- or 60-tick basis).
It is more sophisticated than grab memory per item.
This helped be to understand it better - https://vectree.io/c/memcached-internals-slab-allocation-lru...
The article mentions the default value is a null, which would be the cue to run whatever computationally expensive op or query the db or hit the disk etc... that you would normally run if you had no cache to begin with.
> but screwdrivers make great hammers too
I don't know what your screwdrivers look like but that sounds like a rough time.
“Anyways, Redis homepage aside, you deploy it, and off you go - your trusty cache. You hand the connection string to the people who asked for it, and off you go.”
“None of these things are impossible with Redis, it’s just that memcached’s architecture in general more leans towards these directions, which makes it much, much more straightforward from an operations point of view.”
{kind=link}