It looks and sounds incredibly powerful on paper. But the reality is drastically different. It's a big glob of homegrown thoughts and ideas. Some of them are really slick, like build deduplication. Others are clever and hard to reason about, or in the worst case, terrifying to touch.
We had to fork BuildKit very early in our Depot journey. We've fixed a ton of things in it that we hit for our use case. Some of them we tried to upstream early on, but only for it to die on the vine for one reason or another.
Today, our container builders are our own version of BuildKit, so we maintain 100% compatibility with the ecosystem. But our implementation is greatly simplified. I hope someday we can open-source that implementation to give back and show what is possible with these ideas applied at scale.
It's clear a ton of care has gone into the product, and I also appreciated you personally jumping onto some of my support tickets when I was just getting things off the ground.
This is true of packaging and build systems in general. They are often the passion projects of one or a handful of people in an organization - by the time they have active outside development, those idiosyncratic concepts are already ossified.
It's really rare to see these sorts of projects decomposed into building blocks even just having code organization that helps a newcomer understand. Despite all the code being out in public, all the important reasoning about why certain things are the way they are is trapped inside a few dev's heads.
Managers and executives are happy to hear that you made the builds faster or more reliable, so the infra people who care about this kind of thing don't waste time on design docs and instead focus on getting to a minimum prototype that demonstrates those improved metrics. Once you have that, then there's buy-in and the project is made official... but by then the bones have already been set in place, so design documentation ends up focused on the more visible stuff like user interface, storage formats, etc.
What nobody tells you is that the cache mount is local to the builder daemon. If you're running builds on ephemeral CI instances, those caches are gone every build and you're back to square one. The registry cache backend exists to solve this but it adds enough complexity that most teams give up and just eat the slow builds.
The other underrated BuildKit feature is the ssh mount. Being able to forward your SSH agent into a build step without baking keys into layers is the kind of thing that should have been in Docker from day one. The number of production images I've seen with SSH keys accidentally left in intermediate layers is genuinely concerning.
But the real hidden power of buildkit is the ability to swap out the Dockerfile parser. If you want to see that in action, look at this Dockerfile (yes, that's yaml) used for one of their hardened images: https://github.com/docker-hardened-images/catalog/blob/main/...
The code first options are quite good these days, but you can get so far with make & other legacy tooling. Docker feels like a company looking to sell enterprise software first and foremost, not move the industry standard forward
great article tho!
Compared to a Dockerfile it's just too hard to follow
Edit: The claim about the hash being the same is incorrect, but an identical Dockerfile can produce different outputs on different machines/days whereas nix will always produce the same output for a given input.
If they didn't take shortcuts. I don't know if it's been fixed, but at one point Vuze in nix pulled in an arbitrary jar file from a URL. I had to dig through it because the jar had been updated at some point but not the nix config and it was failing at an odd place.
The cache key includes the state of the filesystem so I don’t think that would ever be true.
Regardless, the purpose of the tool is to generate [layer] images to be reused, exactly to avoid the pitfalls of reproducible builds, isn’t it? In the context of the article, what makes builds reproducible is the shared cache.
Also, there is nothing stopping you from creating a container that has make + tools required to compile your source code, writing a dockerfile that uses those tools to produce the output and leave it on the file system. Why that approach? Less friction for compiling since I find most make users have more pet build servers then cattle or making modifications can have a lot of friction due to conflicts.
BuildKit is very cool tech, but painful to run at volume
Fun gotchya in BuildKit direct versus Dockerfiles, is the map iteration you loaded those ENV vars into consistent? No, that's why your cache keeps getting busted. You can't do this in the linear Dockerfile
Everything runs in its own docker runner. New buildkitd service for every job. Caching only via buildkit native cache export. Output format oci image compressed with zstd. Works pretty great so far, same or faster builds and we now create multi arch images. All on rootless runners by the way
Had to recently make it so multiple versions can run on the same host, such that as developers change branches, which may be on different IaC'd versions (we launch on demand), we don't break LTS release branches.
It sounds great in theory, but it JustDoesn'tWork(tm).
Its caching is plain broken, and the overhead of transmitting the entire build state to the remote computer every time is just busywork for most cases. I switched to Podman+buildah as a result, because it uses the previous dead simple Docker layered build system.
If you don't believe me, try to make caching work on Github with multi-stage images. Just have a base image and a couple of other images produced from it and try to use the GHA cache to minimize the amount of pulled data.
It's yet one more incomprehensible Buildkit decision. The original Docker builder had a very simple cache system: it computed the layer hash and then checked the registry for its presence. Simple content-addressable caching.
Buildkit can NOT do this. Instead, it uses a single image as a dumping ground for the caches. If you have two builders using the same image, they'll step on each other's toes. GHA at least side-steps this.
But I tried the registry cache, and it didn't improve anything. So far, I was not able to get caching to work with multi-stage builds at all. There are open issues for that, dating back to 2020.
I find that buildah is sort of unbearably slow when using dockerfiles...
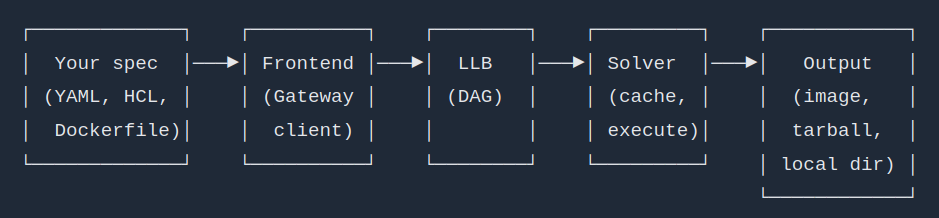
https://tuananh.net/img/buildkit-llb.png
Maybe the page was changed? If you're just talking about the gaps between lines, that's just the line height in whatever source was used to render the image, which doesn't say much about AI either way.
{kind=link}